


gin框架源码之请求处理流程解析
起步
首先我们去初始化一个gin的web项目 https://gin-gonic.com/zh-cn/docs/quickstart/
package main
import (
"github.com/gin-gonic/gin"
"net/http"
)
func main() {
r := gin.Default()
r.GET("/", func(context *gin.Context) {
context.JSON(http.StatusOK, nil)
})
r.Run()
}
从gin的入口 Run 开始!
func (engine *Engine) Run(addr ...string) (err error) {
defer func() { debugPrintError(err) }()
if engine.isUnsafeTrustedProxies() {
debugPrint("[WARNING] You trusted all proxies, this is NOT safe. We recommend you to set a value.\n" +
"Please check https://pkg.go.dev/github.com/gin-gonic/gin#readme-don-t-trust-all-proxies for details.")
}
address := resolveAddress(addr)
debugPrint("Listening and serving HTTP on %s\n", address)
err = http.ListenAndServe(address, engine.Handler())
return
}
核心代码在11行,可以看到gin内部是使用 net.http 标准库,通过 ListenAndServe 方法启动一个http 服务!
// ListenAndServe always returns a non-nil error.
func ListenAndServe(addr string, handler Handler) error {
server := &Server{Addr: addr, Handler: handler}
return server.ListenAndServe()
}
net.http 标准库的ListenAndServe:第一个参数接受一个地址!第二个参数接受一个实现了 Handler 接口的参数!
type Handler interface {
ServeHTTP(ResponseWriter, *Request)
}
定位到这个接口,在goland编辑器中,我们可以点击接口旁边的一个带这个下箭头的图标,点击一下就可以看到都有哪些实现了这个接口
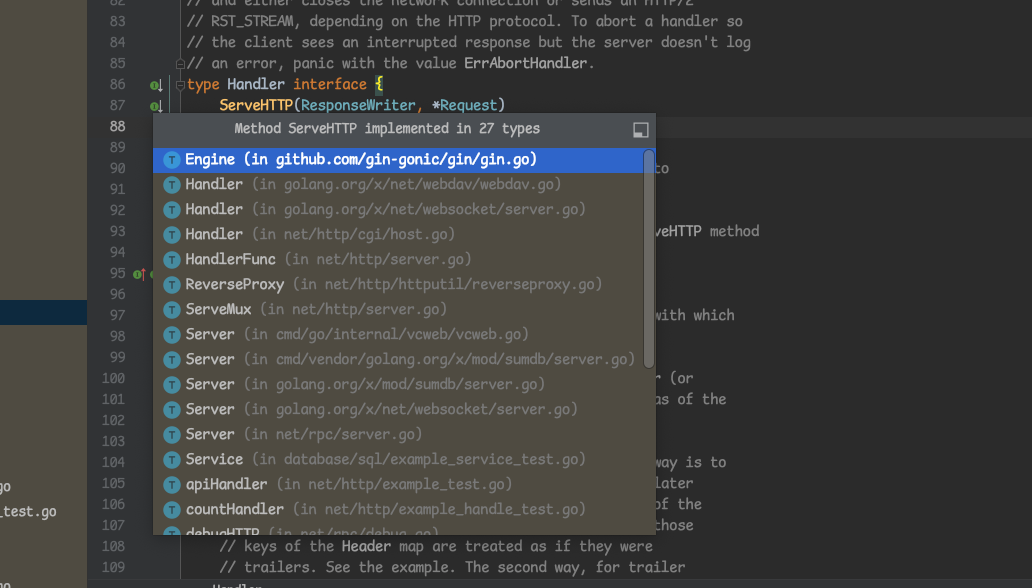
可以看到第一个 gin.Engine 就是我们要找的!
// ServeHTTP conforms to the http.Handler interface.
func (engine *Engine) ServeHTTP(w http.ResponseWriter, req *http.Request) {
// 对象池 为了减少对象频繁创建申请和gc销毁(回收)的消耗!(一个对象在这个池子里反复的使用)
c := engine.pool.Get().(*Context)
// 初始化,因为对象池中,很多地方公用一个对象,为了防止引用互相造成影响,那么就需要对这个对象进行一个初始化!
c.writermem.reset(w)
c.Request = req
c.reset()
// 处理http请求!
engine.handleHTTPRequest(c)
// 请求完了就放回池子!
engine.pool.Put(c)
}
然后在进入核心的 engine.handleHTTPRequest(c) 看他是怎么处理的!
当然其实内部比较重要的就是处理路由树的那一段代码~
// Find root of the tree for the given HTTP method
t := engine.trees // 拿出gin 引擎的路由树,然后进行遍历!
这个树是methodTrees类型!也就是我们这里重点要去看的!
type methodTree struct {
method string
root *node
}
type methodTrees []methodTree
methodTree 提供了一个get方法,你可以根据method的方法,获取当前方法的请求树[遍历匹配method!]
func (trees methodTrees) get(method string) *node {
for _, tree := range trees {
if tree.method == method {
return tree.root
}
}
return nil
}
root是一个 node 类型的结构体
// tree.go
type node struct {
path string
indices string
wildChild bool
nType nodeType
priority uint32
children []*node // child nodes, at most 1 :param style node at the end of the array
handlers HandlersChain
fullPath string
}
path:表示的是路径 /search /support
indices:保存的是分裂的分支的第一个字符,例如search和support, 那么s节点的indices对应的"eu"代表有两个分支, 分支的首字母分别是e和u
wildChild:节点是否是参数节点,比如上面的:post
nType:节点类型,包括 static, root, param, catchAll
- static: 静态节点(默认),比如上面的s,earch等节点
- root: 树的根节点
- catchAll: 有*匹配的节点
- param: 参数节点
priority:优先级,子节点、子子节点等注册的handler数量
children []*node:儿子节点!
handlers:处理函数链条(切片)type HandlersChain []HandlerFunc
fullPath:完整路径
总结一下
路由树 methodTrees 是一个 methodTree 的切片!对应着不同的请求方法!去存对应请求方法的路由树!
因为http请求的方法就那么几种是固定的!所以我们可以进入 gin.Default() 去看gin引擎的初始化方法!
// gin.go
func Default() *Engine {
debugPrintWARNINGDefault()
engine := New()
engine.Use(Logger(), Recovery())
return engine
}
func New() *Engine {
debugPrintWARNINGNew()
engine := &Engine{
RouterGroup: RouterGroup{
Handlers: nil,
basePath: "/",
root: true,
},
FuncMap: template.FuncMap{},
RedirectTrailingSlash: true,
RedirectFixedPath: false,
HandleMethodNotAllowed: false,
ForwardedByClientIP: true,
RemoteIPHeaders: []string{"X-Forwarded-For", "X-Real-IP"},
TrustedPlatform: defaultPlatform,
UseRawPath: false,
RemoveExtraSlash: false,
UnescapePathValues: true,
MaxMultipartMemory: defaultMultipartMemory,
trees: make(methodTrees, 0, 9),
delims: render.Delims{Left: "{{", Right: "}}"},
secureJSONPrefix: "while(1);",
trustedProxies: []string{"0.0.0.0/0", "::/0"},
trustedCIDRs: defaultTrustedCIDRs,
}
engine.RouterGroup.engine = engine
engine.pool.New = func() any {
return engine.allocateContext(engine.maxParams)
}
return engine
}
可以看到 trees: make(methodTrees, 0, 9), 实例化 Engine 字段的时候,指定了切片的长度为9,这样也能避免了动态扩容的性能消耗问题!
gin框架源码之路由注册和路由匹配
路由是在什么时候注册的呢?
package main
import (
"github.com/gin-gonic/gin"
"net/http"
)
func main() {
r := gin.Default()
r.GET("/hello", func(context *gin.Context) {
context.JSON(http.StatusOK, nil)
})
r.Run()
}
其实很简单就能知道,当程序运行的时候,执行到 r.GET 的时候,其实就是注册路由的过程!传入一个path和一个对应的处理函数handler!
那么这个GET方法其实就是用来注册路由的函数!我们可以点进去看看 GET方法是什么样子
// routergroup.go
func (group *RouterGroup) GET(relativePath string, handlers ...HandlerFunc) IRoutes {
return group.handle(http.MethodGet, relativePath, handlers)
}
-
第一个参数 relativePath 就是接受的路由的path
-
第二个参数是一个
handlers []HandlerFunc你可以传多个处理函数的 handlerr.GET("/hello", func(context *gin.Context) { context.JSON(http.StatusOK, nil) }, func(context *gin.Context) { context.JSON(http.StatusOK, gin.H{ "OK": "OK", }) })
在 routergroup.go 中也能找到其他不同请求方法的注册函数的实现
那么我们看到所有的请求注册入口函数,内部都执行了 group.handle方法!那么我们就去看看 group.handle方法是如何统一去注册所有的路由的!
func (group *RouterGroup) handle(httpMethod, relativePath string, handlers HandlersChain) IRoutes {
absolutePath := group.calculateAbsolutePath(relativePath)
handlers = group.combineHandlers(handlers)
group.engine.addRoute(httpMethod, absolutePath, handlers)
return group.returnObj()
}
首先可以看到,先对路径做了一个转换!因为所有的路由在内部是一个group是维护的!那么其实gin的group是有一个分组路由模式的,可以看下面的代码
r := gin.Default()
t1 := r.Group("/test")
t1.GET("/t1", func(context *gin.Context) {
context.JSON(http.StatusOK, gin.H{
"OK": "OK",
})
})
这样最终生成的路由path就是 GET /test/t1 所以 group 就统一去进行了一次路径的整合!
func (group *RouterGroup) calculateAbsolutePath(relativePath string) string {
return joinPaths(group.basePath, relativePath)
}
那么下一行就是整合全部的路由处理的函数handler
handlers = group.combineHandlers(handlers)
func (group *RouterGroup) combineHandlers(handlers HandlersChain) HandlersChain {
// 计算全部handler的一个长度!
finalSize := len(group.Handlers) + len(handlers)
//不能超出一个 abortIndex的长度
assert1(finalSize < int(abortIndex), "too many handlers")
// 根据长度去初始化一个新的指定长度的切片
mergedHandlers := make(HandlersChain, finalSize)
// 然后把所有的handler整合到一个切片中!返回出去!
copy(mergedHandlers, group.Handlers)
copy(mergedHandlers[len(group.Handlers):], handlers)
return mergedHandlers
}
然后下面就是引擎添加路由了!
group.engine.addRoute(httpMethod, absolutePath, handlers)
传入method,整合过的path,整合过的handlers
func (engine *Engine) addRoute(method, path string, handlers HandlersChain) {
// 一些边界条件判断!
assert1(path[0] == '/', "path must begin with '/'")
assert1(method != "", "HTTP method can not be empty")
assert1(len(handlers) > 0, "there must be at least one handler")
debugPrintRoute(method, path, handlers)
// 下面就是熟悉的把路由放到路由树的操作了!
root := engine.trees.get(method)
if root == nil {
root = new(node)
root.fullPath = "/"
engine.trees = append(engine.trees, methodTree{method: method, root: root})
}
root.addRoute(path, handlers)
// Update maxParams
if paramsCount := countParams(path); paramsCount > engine.maxParams {
engine.maxParams = paramsCount
}
if sectionsCount := countSections(path); sectionsCount > engine.maxSections {
engine.maxSections = sectionsCount
}
}
那么其中root的addRoute方法,其实就是按照radix树的算法,把要注册的路由信息放入到这个radix树中!也不用太纠结内部的具体代码,反正记不住的!分析流程,掺杂太多的使用细节反而不易于理解
路由匹配
当我们将项目跑起来的时候,那么需要进行路由匹配,然后匹配对应的树上的某一个节点,然后去调用路由的处理函数!
其实这里就又回到了!我们去分析路由树的时候的那个函数内部!
func (engine *Engine) handleHTTPRequest(c *Context) {
httpMethod := c.Request.Method
rPath := c.Request.URL.Path
unescape := false
if engine.UseRawPath && len(c.Request.URL.RawPath) > 0 {
rPath = c.Request.URL.RawPath
unescape = engine.UnescapePathValues
}
if engine.RemoveExtraSlash {
rPath = cleanPath(rPath)
}
// Find root of the tree for the given HTTP method
t := engine.trees
for i, tl := 0, len(t); i < tl; i++ {
if t[i].method != httpMethod {
continue
}
root := t[i].root
// Find route in tree
value := root.getValue(rPath, c.params, c.skippedNodes, unescape)
if value.params != nil {
c.Params = *value.params
}
if value.handlers != nil {
c.handlers = value.handlers
c.fullPath = value.fullPath
c.Next()
c.writermem.WriteHeaderNow()
return
}
if httpMethod != http.MethodConnect && rPath != "/" {
if value.tsr && engine.RedirectTrailingSlash {
redirectTrailingSlash(c)
return
}
if engine.RedirectFixedPath && redirectFixedPath(c, root, engine.RedirectFixedPath) {
return
}
}
break
}
if engine.HandleMethodNotAllowed {
for _, tree := range engine.trees {
if tree.method == httpMethod {
continue
}
if value := tree.root.getValue(rPath, nil, c.skippedNodes, unescape); value.handlers != nil {
c.handlers = engine.allNoMethod
serveError(c, http.StatusMethodNotAllowed, default405Body)
return
}
}
}
c.handlers = engine.allNoRoute
serveError(c, http.StatusNotFound, default404Body)
}
当匹配到了路由信息,会有执行 getValue,这个函数就是根据路径去查找对应的一些处理请求的值!
value := root.getValue(rPath, c.params, c.skippedNodes, unescape)
func (n *node) getValue(path string, params *Params, skippedNodes *[]skippedNode, unescape bool) (value nodeValue) {
var globalParamsCount int16
....
getValue 这个函数返回的是一个nodeValue结构体!
// nodeValue holds return values of (*Node).getValue method
type nodeValue struct {
handlers HandlersChain // 处理 path 对应的函数链 切片类型 type HandlersChain []HandlerFunc
params *Params // 在路由匹配阶段捕获到的参数!
tsr bool
fullPath string
}
handlers HandlersChain:处理 path 对应的函数链 切片类型 type HandlersChain []HandlerFunc
params *Params:在路由匹配阶段捕获到的参数! type Params []Param
Params是路由器返回的
Param-slice。切片已排序,第一个URL参数也是第一个切片值。
因此,按索引读取值是安全的。
Params 实现了一个 Get方法,用于获取参数的值
// Param是一个单独的URL参数,由一个键和一个值组成。
type Param struct {
Key string
Value string
}
// 根据 name 获取 Param 的值,如果匹配则返回 [value,true] 否则返回空字符串和 false['',fasle]
func (ps Params) Get(name string) (string, bool) {
for _, entry := range ps {
if entry.Key == name {
return entry.Value, true
}
}
return "", false
}
拿到了 nodeValue 就等于 拿到了 路径参数和处理函数
if value.params != nil {
c.Params = *value.params
}
if value.handlers != nil {
c.handlers = value.handlers
c.fullPath = value.fullPath
c.Next()
c.writermem.WriteHeaderNow()
return
}
往下走,做了一些边界判断!然后如果存在则保存在context
这里当处理函数的时候,可以看到进入了一个Next()方法
func (c *Context) Next() {
c.index++
for c.index < int8(len(c.handlers)) {
c.handlers[c.index](c)
c.index++
}
}
这里是对全部的路由处理函数进行循环调用执行!那么到这里呢~我们就大致能明白了,这些路由是如何匹配并执行的流程了!
评论区