


参考链接
- https://juejin.cn/post/7032091256457003044
- https://www.liwenzhou.com/posts/Go/zap/#autoid-1-3-4
- 等级由低到高:
debug<info<warn<Error<Fatal;
日志需求
一个好的日志记录器都需要能够提供下面哪些功能?
- 良好日志写入性能
- 支持不同的日志级别。并且可分离成多个日志文件
- 多输出 - 同时支持标准输出,文件等
- 能够打印基本信息,如调用文件 / 函数名和行号,日志时间等
- 可读性与结构化,Json格式或有分隔符,方便后续的日志采集、监控等
- 文件切割,可按小时、天进行日志拆分,或者按文件大小
默认的Go Logger
Go语言提供的默认日志包是https://golang.org/pkg/log/。
配置一下日志输出的文件地址
package initialization
import (
"log"
"os"
)
func InitGoLogger() {
// 1.打开一个文件,若不存在,则根据标志 选择是否创建 https://pkg.go.dev/os?utm_source=gopls#OpenFile
logFileLocation, _ := os.OpenFile("./test.log", os.O_CREATE|os.O_APPEND|os.O_RDWR, 0744)
// 2.SetOutput设置标准记录器的输出目的地。func SetOutput(w io.Writer)
log.SetOutput(logFileLocation)
}
封装一个简单的http get请求函数,内部用我们的 log 标准库去记录错误日志!
func simpleHttpGet(url string) {
resp, err := http.Get(url)
if err != nil {
log.Printf("Error fetching url %s : %s", url, err.Error())
} else {
log.Printf("Status Code for %s : %s", url, resp.Status)
resp.Body.Close()
}
}
func main() {
initialization.InitGoLogger()
simpleHttpGet("https://www.baidu.com")
simpleHttpGet("www.google.com")
}
可以看到当前目录会生成 ./test.log 文件
2023/02/19 22:28:44 Status Code for https://www.baidu.com : 200 OK
2023/02/19 22:28:44 Error fetching url www.google.com : Get "www.google.com": unsupported protocol scheme ""
Go Logger的优势和劣势
优势
它最大的优点是使用非常简单。我们可以设置任何 io.Writer 作为日志记录输出并向其发送要写入的日志。
劣势
-
仅限基本的日志级别
- 只有一个
Print选项。不支持INFO/DEBUG等多个级别。
- 只有一个
-
对于错误日志,它有
Fatal和PanicFatal日志通过调用os.Exit(1)来结束程序Panic日志在写入日志消息之后抛出一个panic- 但是它缺少一个ERROR日志级别,这个级别可以在不抛出panic或退出程序的情况下记录错误
-
缺乏日志格式化的能力 —— 例如记录调用者的函数名和行号,格式化日期和时间格式。等等。
-
不提供日志切割的能力。
主角-Uber-go Zap
为什么选择Uber-go zap
- 它同时提供了结构化日志记录和printf风格的日志记录
- 它非常的快
根据Uber-go Zap的文档,它的性能比类似的结构化日志包更好——也比标准库更快。 以下是Zap发布的基准测试信息
记录一条消息和10个字段:
| Package | Time | Time % to zap | Objects Allocated |
|---|---|---|---|
| ⚡️ zap | 862 ns/op | +0% | 5 allocs/op |
| ⚡️ zap (sugared) | 1250 ns/op | +45% | 11 allocs/op |
| zerolog | 4021 ns/op | +366% | 76 allocs/op |
| go-kit | 4542 ns/op | +427% | 105 allocs/op |
| apex/log | 26785 ns/op | +3007% | 115 allocs/op |
| logrus | 29501 ns/op | +3322% | 125 allocs/op |
| log15 | 29906 ns/op | +3369% | 122 allocs/op |
记录一个静态字符串,没有任何上下文或printf风格的模板:
| Package | Time | Time % to zap | Objects Allocated |
|---|---|---|---|
| ⚡️ zap | 118 ns/op | +0% | 0 allocs/op |
| ⚡️ zap (sugared) | 191 ns/op | +62% | 2 allocs/op |
| zerolog | 93 ns/op | -21% | 0 allocs/op |
| go-kit | 280 ns/op | +137% | 11 allocs/op |
| standard library | 499 ns/op | +323% | 2 allocs/op |
| apex/log | 1990 ns/op | +1586% | 10 allocs/op |
| logrus | 3129 ns/op | +2552% | 24 allocs/op |
| log15 | 3887 ns/op | +3194% | 23 allocs/op |
安装
go get -u go.uber.org/zap
选择一个Logger
Zap提供了两种类型的日志记录器—Sugared Logger和Logger。
在性能很好但并不关键的情况下,可以使用SugaredLogger。它比其他结构化日志包快4-10倍,同时支持结构化和printf式日志。
像log15和go-kit一样,SugaredLogger的结构化日志API是松散的类型,接受不同数量的键值对。(对于更高级的用例,它们也接受强类型的字段–详见SugaredLogger.With文档)。
func main() {
sugar := zap.NewExample().Sugar()
defer sugar.Sync()
sugar.Infow("failed to fetch URL",
"url", "http://example.com",
"attempt", 3,
"backoff", time.Second,
"自定义+++", "自定义吱吱吱",
)
sugar.Infof("failed to fetch URL: %s", "http://example.com")
}
╰─ go run main.go ─╯
{"level":"info","msg":"failed to fetch URL","url":"http://example.com","attempt":3,"backoff":"1s","自定义+++":"自定义吱吱吱"}
{"level":"info","msg":"failed to fetch URL: http://example.com"}
在极少数情况下,每个微秒和每个分配都很重要,请使用 Logger。它甚至比SugaredLogger更快,而且分配的资源少得多,但它只支持强类型的结构化日志。
func main() {
logger := zap.NewExample()
defer logger.Sync()
logger.Info("failed to fetch URL",
// 强类型的结构化 指的是类型确定不像 sugar 那样随便写!
zap.String("url", "http://example.com"),
zap.Int("attempt", 3),
zap.Duration("backoff", time.Second),
zap.String("自定义+++", "自定义吱吱吱"),
)
}
配置Zap
构建Logger的最简单的方法是使用zap的意见预设。NewExample, NewProduction, and NewDevelopment。这些预设只需调用一个函数就可以建立一个记录器。
- 上面的每一个函数都将创建一个logger。唯一的区别在于它将记录的信息不同。例如production logger默认记录调用函数信息、日期和时间等。
- 通过Logger调用Info/Error等。
- 默认情况下日志都会打印到应用程序的console界面。
var logger *zap.Logger // 全局变量
logger, err = zap.NewProduction() // 初始化
在一个函数里面使用 logger 将simpleHttpGet的logger替换成zap.logger!
func simpleHttpGet(url string) {
resp, err := http.Get(url)
if err != nil {
logger.Error(
"Error fetching url..",
zap.String("url", url),
zap.Error(err))
} else {
logger.Info("Success..",
zap.String("statusCode", resp.Status),
zap.String("url", url))
resp.Body.Close()
}
}
执行!打印控制台!可以看到。默认记录调用函数信息、日期和时间
go run main.go
{"level":"info","ts":1676818688.0260448,"caller":"restrat!/main.go:43","msg":"Success..","statusCode":"200 OK","url":"http://www.baidu.com"}
Sugared Logger和logger的切换自如
在Logger和SugaredLogger之间的选择不需要是整个应用的决定:在两者之间的转换很简单,而且成本很低。
logger := zap.NewExample()
defer logger.Sync()
sugar := logger.Sugar()
plain := sugar.Desugar()
func simpleHttpGet(url string) {
resp, err := http.Get(url)
if err != nil {
// 上面已经讲到过!sugar更加松散自由一点哈哈!
suggerLogger.Errorf("Error fetching URL %s : Error = %s", url, err)
} else {
suggerLogger.Infof("Success! statusCode = %s for URL %s", resp.Status, url)
resp.Body.Close()
}
}
go run main.go
{"level":"info","ts":1676818920.452342,"caller":"restrat!/main.go:41","msg":"Success! statusCode = 200 OK for URL http://www.baidu.com"}
你应该注意到的了,到目前为止这两个logger都打印输出JSON结构格式。
定制logger
需求:
-
将日志输出到多个位置.将日志写入文件+终端
-
将JSON Encoder更改为普通的Log Encoder
-
更改时间编码 1.572161051846623e+09 => 2023-02-19T22:53:16.764+0800
-
添加调用者更为详细的信息
-
将err级别日志单独输出到文件
-
日志切割归档
zap.New
我们将使用zap.New(…)方法来手动传递所有配置,而不是使用像zap.NewProduction()这样的预置方法来创建logger。
func New(core zapcore.Core, options ...Option) *Logger
zap.New 接收一个 zapcore.Core 类型的参数!
zapcore.Core 使用zapcore.NewCore() 生成! zapcore#Core
NewCore创建一个Core,将日志写入WriteSyncer。
func NewCore(enc Encoder, ws WriteSyncer, enab LevelEnabler) Core
需要三个配置::分别指定日志的一些输出规则!
- Encoder 编码器(如何写入日志)
- WriteSyncer 指定日志将写到哪里去
- LogLevel 哪种级别的日志将被写入
Encoder 编码器
Encoder 决定了我们的日志格式!一般我们常用的日志格式有纯文本和json格式
1.NewConsoleEncoder 以纯文本的格式输出,将核心日志条目数据(消息、级别、时间戳等)以纯文本格式序列化,并将结构化的上下文留作JSON格式。
func NewConsoleEncoder(cfg EncoderConfig) Encoder
# Console 日志demo
1.676859498547882e+09 info Success.. {"statusCode": "200 OK", "url": "https://www.baidu.com"}
2.NewJSONEncoder 以 JSON 的格式输出日志!
func NewJSONEncoder(cfg EncoderConfig) Encoder
# JSON 格式 日志demo
{"level":"info","ts":1676859571.1731079,"msg":"Success..","statusCode":"200 OK","url":"https://www.baidu.com"}
这两种构造编码器的函数都接受一个EncoderConfig 编码器配置 EncoderConfig EncoderConfig 允许用户配置 zapcore 提供的具体编码器。
一般我们可以使用 zap 提供的默认配置项 zap.NewDevelopmentEncoderConfig 或者 zap.NewProductionEncoderConfig()
encoder := zapcore.NewConsoleEncoder(zap.NewProductionEncoderConfig())
WriteSyncer
WriteSyncer是一个io.Writer,它也可以冲洗任何缓冲的数据。注意,
*os.File(os.Stderr和os.Stdout)实现了WriteSyncer。
AddSync 将一个io.Writer转换为WriteSyncer
一般我们都会创建一个文件句柄!然后通过 AddSync 将其转换为 WriteSyncer 这一步我们 NewCore的第二个参数就搞定了!
func retLogWriteSyncer() zapcore.WriteSyncer {
file, _ := os.Create("./test.log")
return zapcore.AddSync(file)
}
LogLevel
https://pkg.go.dev/go.uber.org/zap@v1.24.0/zapcore#Level 直接指定内置的就好了!
第一版基础定制
那么理解了上面的参数,我们来组合一个基础版本的!
func retLogWriteSyncer() zapcore.WriteSyncer {
file, _ := os.Create("./test.log")
return zapcore.AddSync(file)
}
func main() {
encoder := zapcore.NewJSONEncoder(zap.NewProductionEncoderConfig())
ws := retLogWriteSyncer()
core := zapcore.NewCore(encoder, ws, zap.DebugLevel)
logger = zap.New(core)
simpleHttpGet("https://www.baidu.com")
}
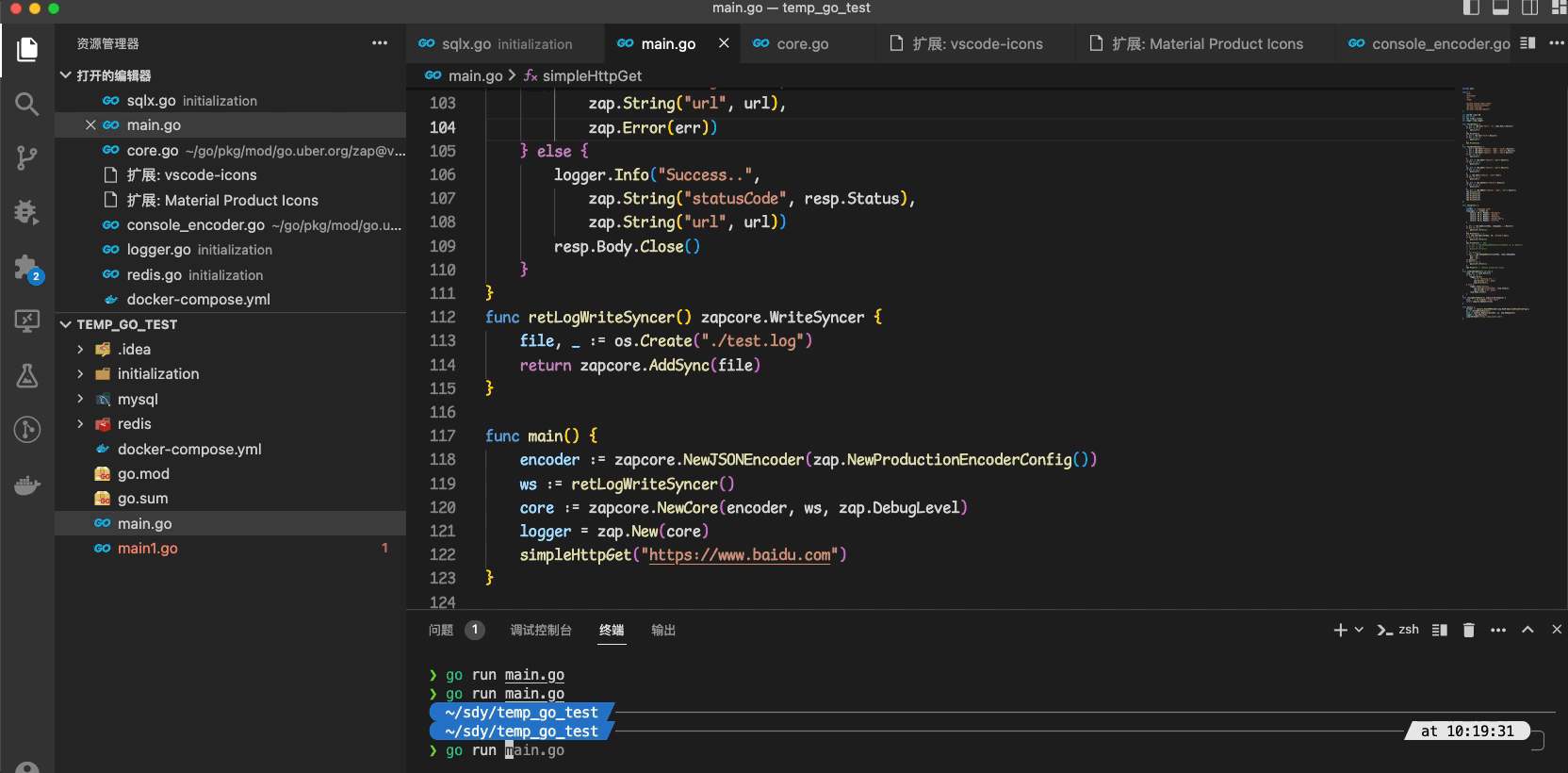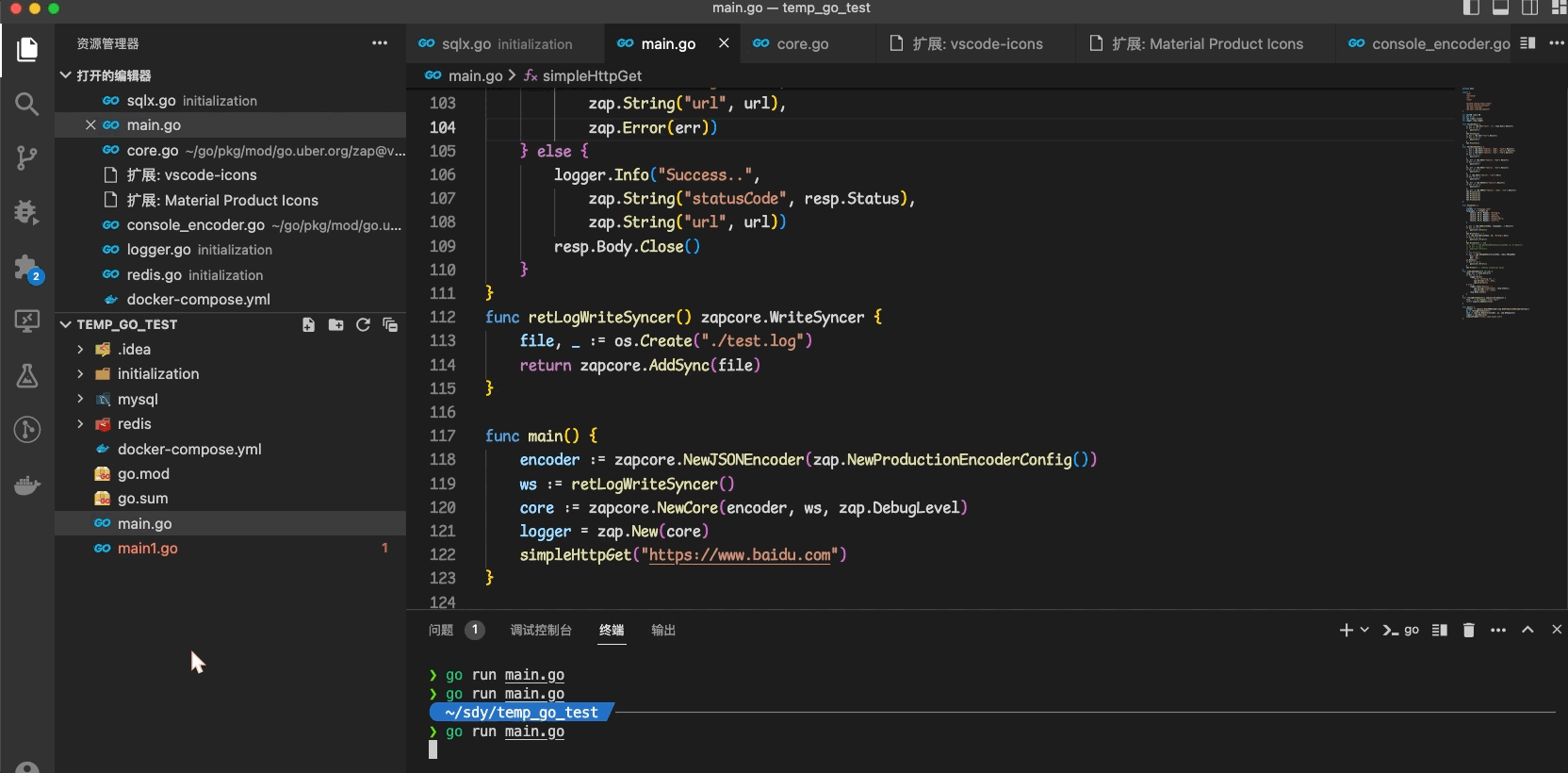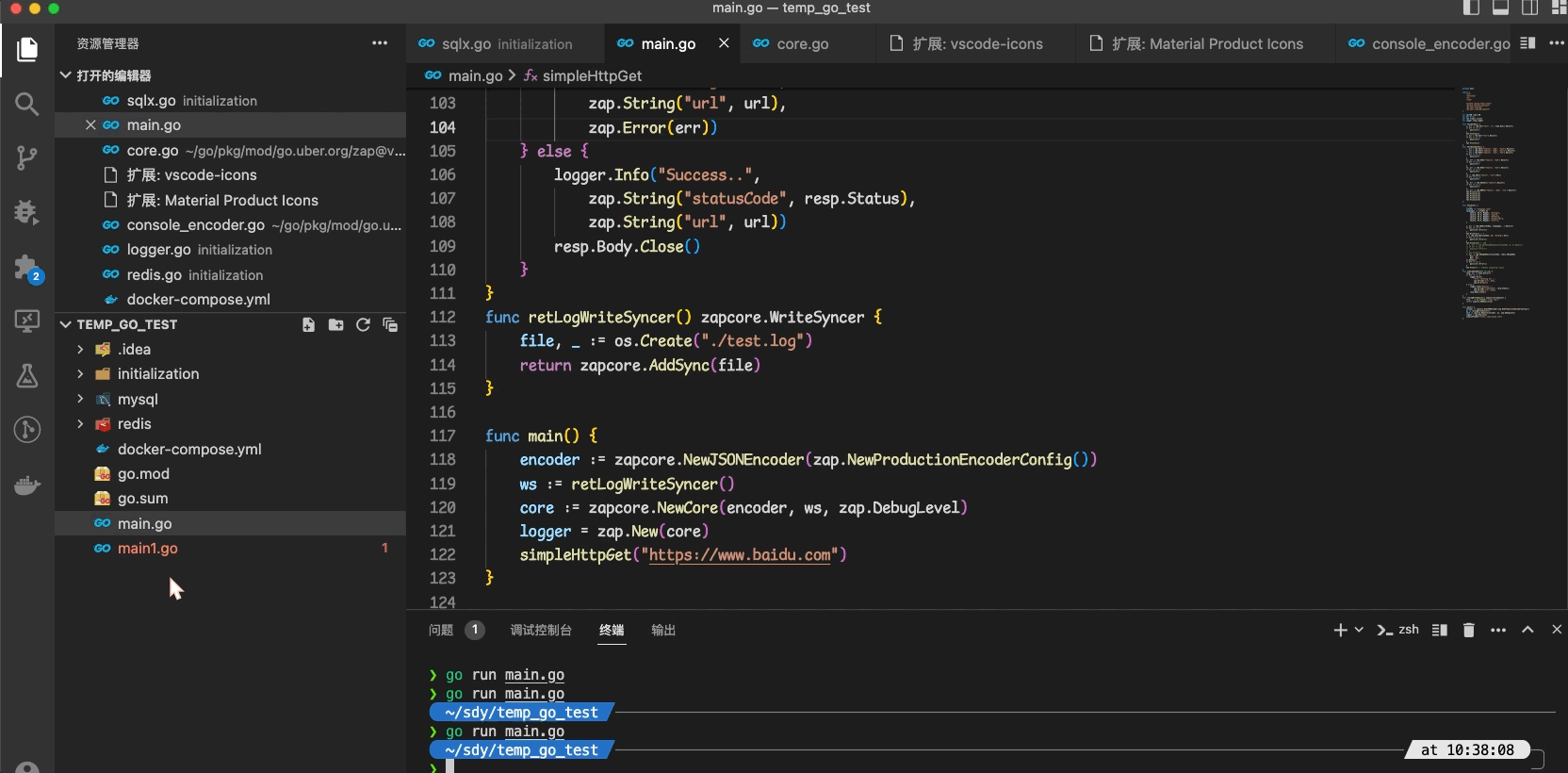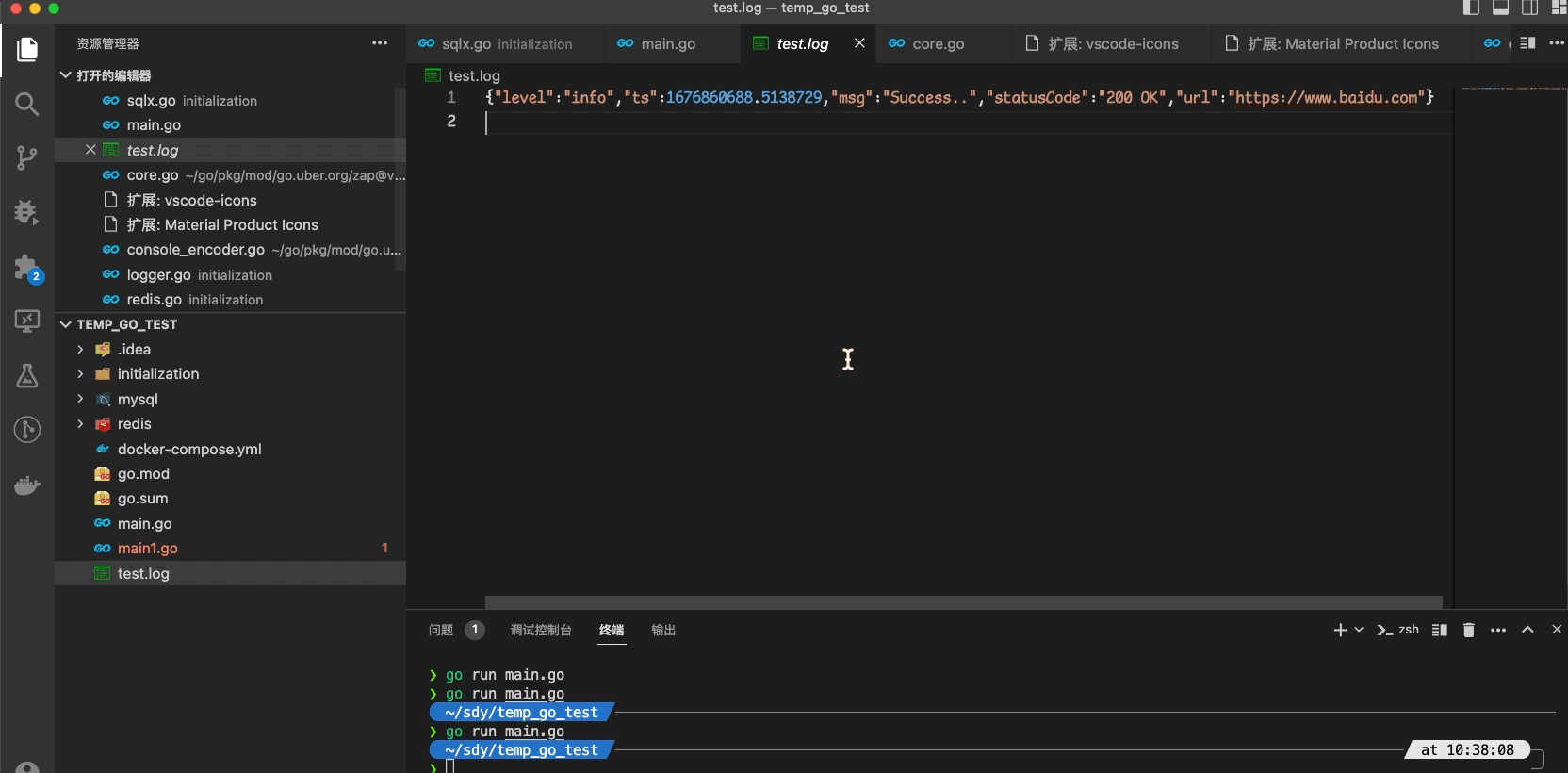
默认配置下 NewProductionEncoderConfig 的日志demo
{"level":"info","ts":1676861655.696921,"msg":"Success..","statusCode":"200 OK","url":"https://www.baidu.com"}
默认配置下 NewDevelopmentEncoderConfig 的日志demo
{"L":"INFO","T":"2023-02-20T10:49:07.569+0800","M":"Success..","statusCode":"200 OK","url":"https://www.baidu.com"}
可以看到! 两种配置的时间戳是不同的!NewProductionEncoderConfig 时间戳的可读性不是很友好!而且两个都缺少了函数调用栈的信息!
修改 NewProductionEncoderConfig 时间戳
- 修改时间编码器
- 在日志文件中使用大写字母记录日志级别(顺带~hhh)
我们可以直接修改配置的字段就好了!
encoderConfig := zap.NewProductionEncoderConfig()
encoderConfig.EncodeTime = zapcore.ISO8601TimeEncoder // 修改 encodetime
encoderConfig.EncodeLevel = zapcore.CapitalLevelEncoder // 日志等级大写!
encoder := zapcore.NewConsoleEncoder(encoderConfig)
这样我们 NewProductionEncoderConfig 的日志输出的时间戳就改好了!
{"level":"INFO","ts":"2023-02-20T11:03:36.556+0800","msg":"Success..","statusCode":"200 OK","url":"https://www.baidu.com"}
添加将调用函数信息记录到日志中 AddCaller & AddCallerSkip
func New(core zapcore.Core, options ...Option) *Logger 支持添加多个 option 这里我们添加一个 zap 内置的 AddCaller
AddCaller配置 Logge,用文件名、行号和zap的调用者的函数名来注释每条消息。
logger = zap.New(core, zap.AddCaller())
调用log , 可以看到多了一个 caller 字段! "caller":"temp_go_test/main.go:106"
{"level":"INFO","ts":"2023-02-20T11:25:25.204+0800","caller":"temp_go_test/main.go:106","msg":"Success..","statusCode":"200 OK","url":"https://www.baidu.com"}
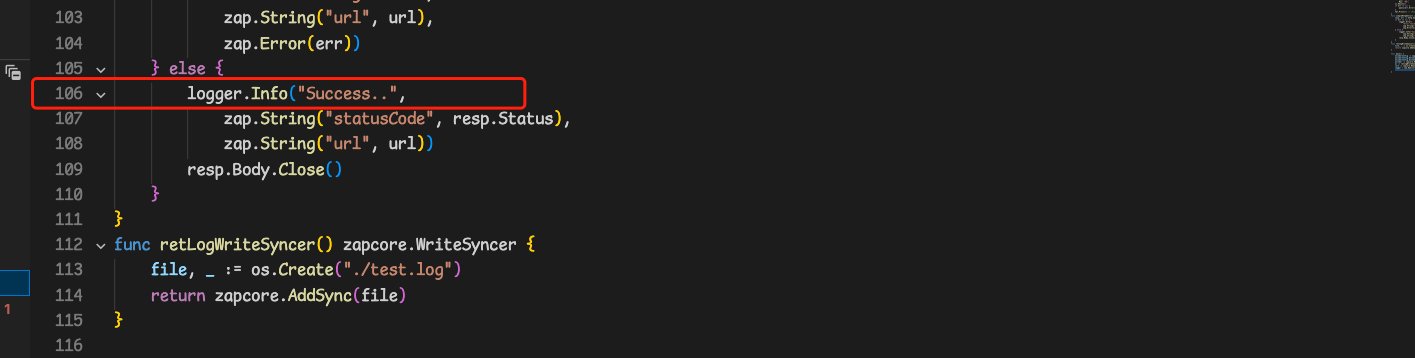
但是如果这个函数被调用了多次!我们再去看一下日志!可以看到这些caller都是指向同一个地方!这样是不是就不够准确呢?

所以zap提供了一个配置! func AddCallerSkip(skip int) ¶
可以理解为一个函数跳栈的操作!
让他日志记录的caller 往外跳 n 层,那么我们上面的 simpleHttpGet 其实相当于在里面一层调用了 logger 所以只需要跳一层,就能准确的找到,具体调用的位置了!
logger = zap.New(core, zap.AddCaller(), zap.AddCallerSkip(1))
simpleHttpGet("https://www.baidu.com")
simpleHttpGet("https://www.baidu.com")
simpleHttpGet("https://www.baidu.com")
simpleHttpGet("https://www.baidu.com")
simpleHttpGet("https://www.baidu.com")
执行后我们再来看看对应的日志
{"level":"INFO","ts":"2023-02-20T11:34:55.995+0800","caller":"temp_go_test/main.go:125","msg":"Success..","statusCode":"200 OK","url":"https://www.baidu.com"}
{"level":"INFO","ts":"2023-02-20T11:34:56.033+0800","caller":"temp_go_test/main.go:126","msg":"Success..","statusCode":"200 OK","url":"https://www.baidu.com"}
{"level":"INFO","ts":"2023-02-20T11:34:56.061+0800","caller":"temp_go_test/main.go:127","msg":"Success..","statusCode":"200 OK","url":"https://www.baidu.com"}
{"level":"INFO","ts":"2023-02-20T11:34:56.104+0800","caller":"temp_go_test/main.go:128","msg":"Success..","statusCode":"200 OK","url":"https://www.baidu.com"}
{"level":"INFO","ts":"2023-02-20T11:34:56.164+0800","caller":"temp_go_test/main.go:129","msg":"Success..","statusCode":"200 OK","url":"https://www.baidu.com"}
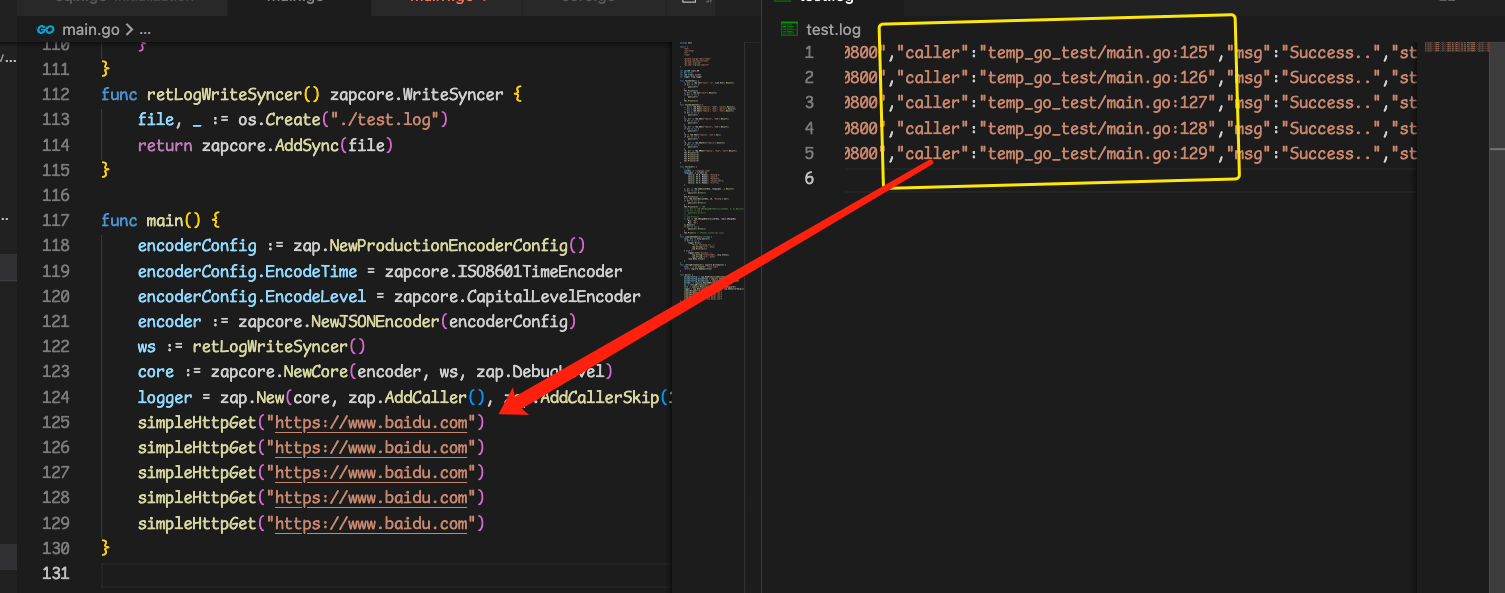
可以看到,他就往外跳了一层去记录!这样就容易找到真正的调用者了!
将日志输出到多个位置(文件+终端)
我们可以将日志同时输出到文件和终端。
可以看到上面只是把日志输出到文件中!利用io.MultiWriter支持文件和终端两个输出目标 os.Stdout 标准输出
func retLogWriteSyncer() zapcore.WriteSyncer {
file, _ := os.Create("./test.log")
ws := io.MultiWriter(file, os.Stdout)
return zapcore.AddSync(ws)
}
总之,zapcore.AddSync 接受一个 io.Writer 去把日志同步到目标就好了!还是很简单的!
将err日志单独输出到文件
我们除了将全量日志输出到xx.log文件中之外,还希望将ERROR级别的日志单独输出到一个名为xx.err.log的日志文件中。我们可以通过以下方式实现。
大致的实现流程就是:为不同级别的 log 实现不同的 core ~ 然后 使用 zap 提供的 NewTee 将多个 core 合并为一个 core !
encoderConfig := zap.NewProductionEncoderConfig()
encoderConfig.EncodeTime = zapcore.ISO8601TimeEncoder
encoderConfig.EncodeLevel = zapcore.CapitalLevelEncoder
encoder := zapcore.NewJSONEncoder(encoderConfig)
ws := retLogWriteSyncer()
ws_err := retLogWriteSyncerErrfile()
core1 := zapcore.NewCore(encoder, ws, zap.DebugLevel) // 等级由低到高:debug<info<warn<Error<Fatal;core1 算是一个收集全部日志的 core 用来输出控制台+文件
core2 := zapcore.NewCore(encoder, ws_err, zap.ErrorLevel) // 这个只用输出error文件就好了!
logger = zap.New(zapcore.NewTee(core1, core2), zap.AddCaller(), zap.AddCallerSkip(1))
simpleHttpGet("https://www.baidu.com")
simpleHttpGet("xxxx")
使用Lumberjack进行日志切割归档
Zap本身不支持切割归档日志文件 官方的说法是为了添加日志切割归档功能,我们将使用第三方库Lumberjack来实现。
目前只支持按文件大小切割,原因是按时间切割效率低且不能保证日志数据不被破坏。详情戳https://github.com/natefinch/lumberjack/issues/54。
想按日期切割可以使用github.com/lestrrat-go/file-rotatelogs这个库,虽然目前不维护了,但也够用了。
执行下面的命令安装 Lumberjack v2 版本。 lumberjack github
go get gopkg.in/natefinch/lumberjack.v2
Lumberjack可以与任何可以写入io.Writer的日志包配合使用,包括标准库的日志包。
zap logger中加入Lumberjack lumberjack.Logger 返回一个带有配置规则的io.Writer
比如我们把之前 debugLevel 日志的 ws 生成函数改造一下
func retLogWriteSyncer() zapcore.WriteSyncer {
// 原来的file io句柄,使用 lumberjack.Logger 替换!
lumberJackLogger := &lumberjack.Logger{
Filename: "./test.log",
MaxSize: 10,
MaxBackups: 5,
MaxAge: 30,
Compress: false,
}
ws := io.MultiWriter(lumberJackLogger, os.Stdout)
return zapcore.AddSync(ws)
}
配置解释:
- Filename: 日志文件的位置
- MaxSize:在进行切割之前,日志文件的最大大小(以MB为单位)
- MaxBackups:保留旧文件的最大个数
- MaxAges:保留旧文件的最大天数
- Compress:是否压缩/归档旧文件
测试一下,比如我们把大小调整为 1m
for i := 0; i < 100000; i++ {
simpleHttpGet("https://www.jianglovehao.space")
}
执行后,发现当文件超出后,会将之前的日志割去 打上时间戳!然后重新创建一个新的 test.log 最新的日志写入 test.log! 如此反复!

整理一下在模块项目中的代码
package initialization
import (
"io"
"os"
"github.com/natefinch/lumberjack"
"go.uber.org/zap"
"go.uber.org/zap/zapcore"
)
/*
TODO :
1.从配置文件来决定用什么 encoder 这里先使用 json
*/
// log 输出编码配置!
func setEncoder() zapcore.Encoder {
encodeConfig := zap.NewProductionEncoderConfig()
encodeConfig.EncodeTime = zapcore.ISO8601TimeEncoder
encodeConfig.EncodeLevel = zapcore.CapitalLevelEncoder
encoder := zapcore.NewJSONEncoder(encodeConfig)
return encoder
}
// log 输出文件io配置
func setIoWriter() zapcore.WriteSyncer {
lg := &lumberjack.Logger{
Filename: "./app.log",
MaxSize: 10,
MaxBackups: 5,
MaxAge: 30,
Compress: false,
}
ws := io.MultiWriter(lg, os.Stdout)
return zapcore.AddSync(ws)
}
// ERROR 级别 log 输出文件io配置
func setErrorLogIoWriter() zapcore.WriteSyncer {
lg := &lumberjack.Logger{
Filename: "./error_app.log",
MaxSize: 10,
MaxBackups: 5,
MaxAge: 30,
Compress: false,
}
return zapcore.AddSync(lg)
}
func InitLogger() (logger *zap.Logger) {
coreAbroveDebug := zapcore.NewCore(setEncoder(), setIoWriter(), zap.DebugLevel)
coreError := zapcore.NewCore(setEncoder(), setErrorLogIoWriter(), zap.ErrorLevel)
core := zapcore.NewTee(coreAbroveDebug, coreError)
logger = zap.New(core, zap.AddCaller(), zap.AddCallerSkip(1))
return
}
评论区