


gin框架源码解析之Radix树介绍
简介
Gin 文档:
参考链接
** 对别人知识的整理!加上自己的理解!**
gin框架使用的是定制版本的httprouter,其路由的原理是大量使用公共前缀的树结构,它基本上是一个紧凑的Trie tree(或者只是Radix Tree)。具有公共前缀的节点也共享一个公共父节点。
Radix Tree
基数树(Radix Tree)又称为PAT位树(Patricia Trie or crit bit tree),是一种更节省空间的前缀树(Trie Tree)。
对于基数树的每个节点,如果该节点是唯一的子树的话,就和父节点合并。下图为一个基数树示例:
所有的节点都以 r 开头 那么 r 就成为了当前基树的根节点~然后看前三的 o 开头的作为下面的节点,其次是 m,但是 m 是 o 的唯一子节点!
所以 m 就和父节点 o 进行了合并,按照这个规律就形成了下面的基数树!
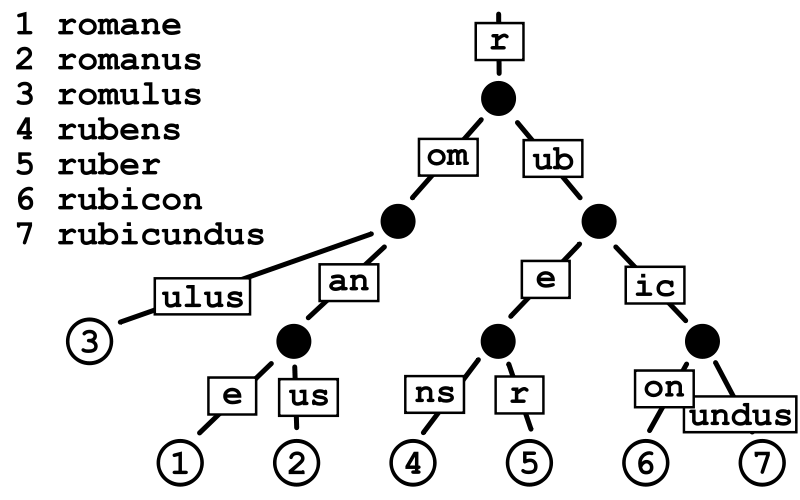
Radix Tree可以被认为是一棵简洁版的前缀树。我们注册路由的过程就是构造前缀树的过程,具有公共前缀的节点也共享一个公共父节点。
假设我们现在注册有以下路由信息:
r := gin.Default()
r.GET("/", func1)
r.GET("/search/", func2)
r.GET("/support/", func3)
r.GET("/blog/", func4)
r.GET("/blog/:post/", func5)
r.GET("/about-us/", func6)
r.GET("/about-us/team/", func7)
r.GET("/contact/", func8)
那么我们会得到一个GET方法对应的路由树,具体结构如下:
Priority Path Handle
9 \ *<1>
3 ├s nil
2 |├earch\ *<2>
1 |└upport\ *<3>
2 ├blog\ *<4>
1 | └:post nil
1 | └\ *<5>
2 ├about-us\ *<6>
1 | └team\ *<7>
1 └contact\ *<8>
- 上面最右边那一列每个
*<数字>表示 Handle 处理函数的内存地址(一个指针) - 从根节点遍历到叶子节点我们就能得到完整的路由表。
例如:blog/:post其中:post只是实际文章名称的占位符(参数)。
与hash-maps不同,这种树结构还允许我们使用像:post参数这种动态部分,因为我们实际上是根据路由模式进行匹配,而不仅仅是比较哈希值。
由于URL路径具有层次结构,并且只使用有限的一组字符(字节值),所以很可能有许多常见的前缀。这使我们可以很容易地将路由简化为更小的问题
此外,路由器为每种请求方法管理一棵单独的树。
一方面,它比在每个节点中都保存一个 method-> handle map 更加节省空间,它还使我们甚至可以在开始在前缀树中查找之前大大减少路由问题。
为了获得更好的可伸缩性,每个树级别上的子节点都按Priority(优先级)排序,其中优先级(最左列)就是在子节点(子节点、子子节点等等)中注册的句柄的数量。【树上的节点越多的话,优先级越高】
为什么要这么做呢?
首先当去匹配一个路由的时候!你在一颗最长的树上找到的概率更大一点!反正你在一颗小树找到的概率就小一点!所以我们优先去做概率大的事情,去找小树的行为也相当于一种赌博~如果直接能在小树上找到那还好,如果没有找到,那么还要去大树中去找!在概率学中,当实验次数达到一定数量级的时候,优先去做大概率成功的事情是最优的选择!
所以一般的路由匹配优先级可以是下面这样~ 每个-可以看做一个节点匹配的路径:从左到右,从上到下。
├------------
├---------
├-----
├----
├--
├--
└-
总结一下
radix树是一种根据公共前缀作为节点的树!这种树的优势在于相对于用map存储来说!运行占用的内存不会那么大!
然后给树节点增加优先级的方式,优化路径查找的效率!
评论区