


最近的一些面试记录【2023/10/23 - 2023/10/26】
你如何理解前端工程化
简单来说,前端工程化可以提升开发体验、提高开发效率和质量、提升应用的访问性能,一切以提高效率、降低成本、质量保证为目的的手段都属于工程化。
前端工程化不等同于Webpack,它主要包含从编码、发布到运维的整个前端研发生命周期,把软件工程相关的方法和思想应用到前端开发。
什么是回流和重绘?以及如何减少?
对前端项目做过哪些优化?
-
静态资源使用 CDN
-
使用字体图标 iconfont 代替图片图标
-
将 CSS 放在文件头部,JavaScript 文件放在底部
-
压缩字体文件
-
图片优化
-
图片延迟加载
-
响应式图片
通过
picture实现复制代码<picture> <source srcset="banner_w1000.jpg" media="(min-width: 801px)"> <source srcset="banner_w800.jpg" media="(max-width: 800px)"> <img src="banner_w800.jpg" alt=""> </picture> -
使用 webp 格式的图片
-
减少重绘重排,用 JavaScript 修改样式时,最好不要直接写样式,而是替换 class 来改变样式。
-
-
使用事件委托
http和https的区别
- HTTPS协议需要到CA申请证书,一般免费证书很少,需要交费。
- HTTP协议运行在TCP之上,所有传输的内容都是明文,HTTPS运行在SSL/TLS之上,SSL/TLS运行在TCP之上,所有传输的内容都经过加密的。
- HTTP和HTTPS使用的是完全不同的连接方式,用的端口也不一样,前者是80,后者是443。
- HTTPS可以有效的防止运营商劫持,解决了防劫持的一个大问题。
vite首次打开界面加载慢问题解决
巨大的请求量加上 Chrome 对同一个域名下只能同时支持 6 个 HTTP 并发请求的限制,导致页面加载十分缓慢,与 Vite 主导性能优势的初衷背道而驰。
总之就是通过添加类似如下的配置,让vite在启动之初就对某些资源进行预打包,尽量避免后续的动态打包,示例配置如下
https://blog.quancundexiwang.wang/2022/12/11/vite-de-yu-gou-jian-gong-neng
数据类型
- 简单数据类型:String、Number、Boolean、Null、Undefined、Symbol。
- 复杂数据类型:Object是唯一的复杂数据类型。 Array Function 这些引用类型值最终都可以归结为 Object 复杂数据类型。
特殊的基本类型:基本包装类型
js为了方便操作基本类型值,ECMAscript 提供了3个特殊的引用类型:Boolean、Number 和 String。每当读取一个基本类型值的时候,后台就会创建一个对应的基本包装类型的对象,从而让我们能够调用一些方法来操作这些数据。``
var s1 = "some text";
// 在这里创建了一个字符串保存在了变量s1,字符串当然是基本类型值。
// 但是此刻我们又调用了s1的方法,基本类型值不是对象,理论上不应该有方法。
//其实,为了让我们实现这种直观的操作,后台已经帮助我们完成了一系列的操作。当我们在第二行代码中访问 s1 变量时,访问过程处于读取模式,而在读取模式中访问字符串时,后台都会自动完成下列处理。
var s2 = s1.substring(2);
// 1. 创建 String 类型的一个实例;
// 2. 在实例上调用指定的方法;
// 3. 销毁这个实例。
var s1 = new String("some text");
var s2 = s1.substring(2);
typeof 返回值
typeof: 对于基本类型出了null(返回 obejct)以外,均可以正确返回。对于复杂类型除了function(返回 function)以外,一律返回object。
HTTP2.0和HTTP1.X相比的新特性
- HTTP/1.* 一次请求-响应,建立一个连接,用完关闭;每一个请求都要建立一个连接;
多路复用,即每一个请求都是是用作连接共享。一个请求对应一个id,这样一个连接上可以有多个请求。二进制格式,HTTP 2.0 使用了更加靠近 TCP/IP 的二进制格式,而抛弃了 ASCII 码,提升了解析效率头部压缩,由于 HTTP 1.1 经常会出现 User-Agent、Cookie、Accept、Server、Range 等字段可能会占用几百甚至几千字节,而 Body 却经常只有几十字节,所以导致头部偏重。HTTP 2.0 使用HPACK算法进行压缩。
说说weakmap
使用weakmap 深拷贝
深拷贝当数据量太大以至于爆内存,改如何解决
把每一次深拷贝的执行函数压入到一个栈数据结构,然后再通过逐个取栈函数执行
防止一次性深拷贝内部缓存占用内存过大,导致内存爆掉。
或者执行中用一种延迟下一次递归执行的方式,比如sleep,防止一次执行太大数据的递归,导致爆内存!
querySelector,getElementsByClassName的区别
- **
getElementsByClassName**一个即时更新的(live)HTMLCollection,包含了所有拥有指定 class 的子元素。 querySelector()方法返回文档中与指定选择器或选择器组匹配的第一个Element对象。如果找不到匹配项,则返回null。Document的方法getElementById()返回一个匹配特定 ID的元素。由于元素的 ID 在大部分情况下要求是独一无二的,这个方法自然而然地成为了一个高效查找特定元素的方法。
使用call+apply或者+bind改变this指向有什么风险吗?
使用call, apply, 或 bind 来改变函数中 this 的指向是一种常见的 JavaScript 技巧,但它们确实存在一些潜在的风险和注意事项:
- 不当使用可能引发错误:如果不正确使用这些方法,可能会导致运行时错误或意外行为。例如,更改绑定的this属性有未定义的风险,或者绑定到一个未定义的函数,都可能导致问题。
const t = {
name: "susan",
age: 12,
sayHi() {
console.log("hi i am", this.name, this.age);
},
};
const q = {
name: "jack",
};
t.sayHi.call(q); // hi i am jack undefined
- 潜在性能开销:在函数调用过程中,使用
call和apply会稍微降低性能,因为它们需要创建一个新的函数上下文并传递参数。这通常不会对性能产生重大影响,但在大量的函数调用中可能会有所感知。 - 增加复杂性:滥用
call,apply, 或bind可能会增加代码的复杂性,使其难以理解和维护。过多的函数上下文的变化可能导致代码难以调试。 - 安全性问题:不当使用这些方法可能导致安全问题,特别是当它们与用户提供的数据一起使用时。恶意用户可以试图篡改函数的上下文,因此要小心不要将不受信任的数据用于这些方法。
- 链式调用问题:在一些情况下,使用
bind可能会导致链式调用的问题,因为它返回一个新函数,而不是原始函数的引用。这可能会干扰期望在链式操作中引用相同对象的情况。
const t = {
name: "susan",
age: 12,
sayHi() {
console.log("hi i am", this.name, this.age);
return this;
},
JustPrintAge(){
console.log("JustPrintAge",this.age)
return this
}
};
const q = {
name: "jack",
sayHi:"just a string"
};
t.sayHi().JustPrintAge()
const nSayHi = t.sayHi.bind(q)
nSayHi().JustPrintAge()
console.log(nSayHi === t.sayHi); // false
console.log(Object.is(nSayHi, t.sayHi));// false

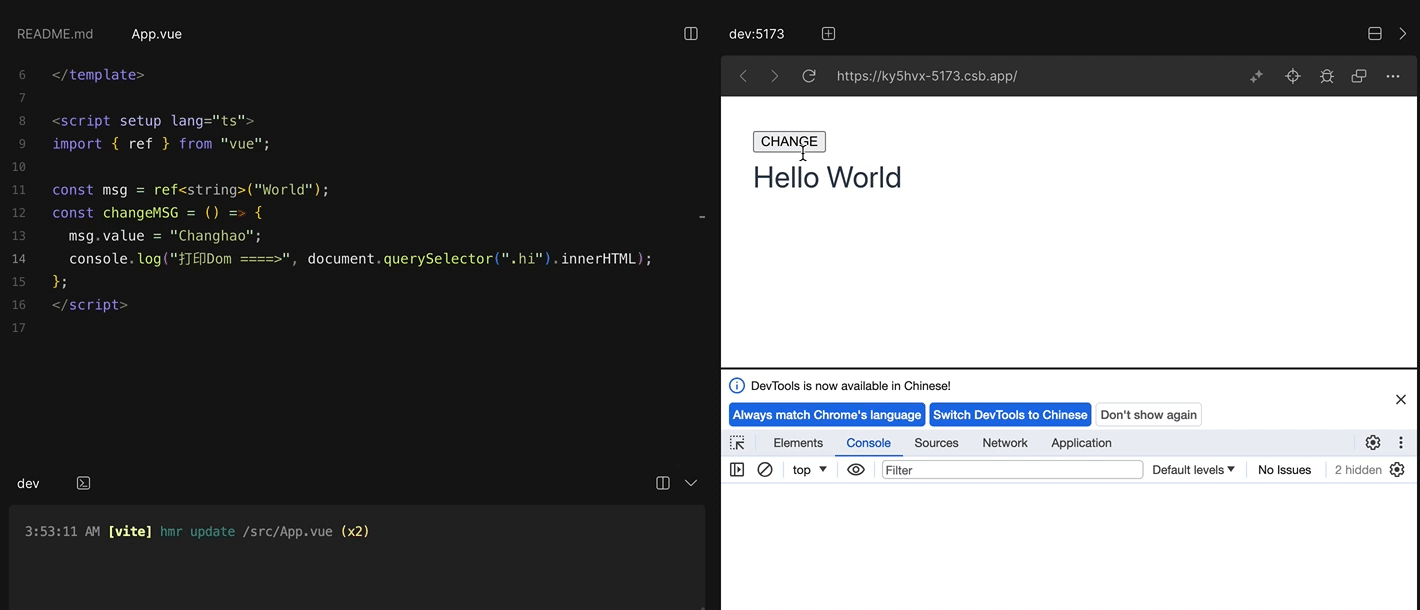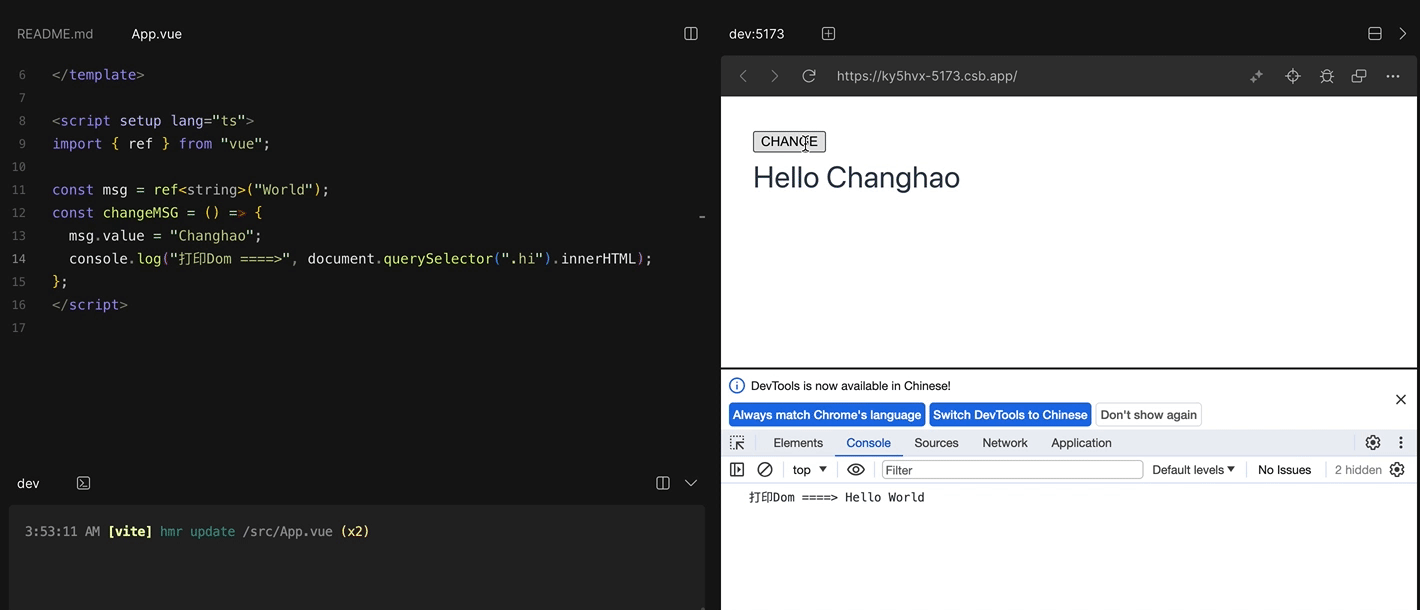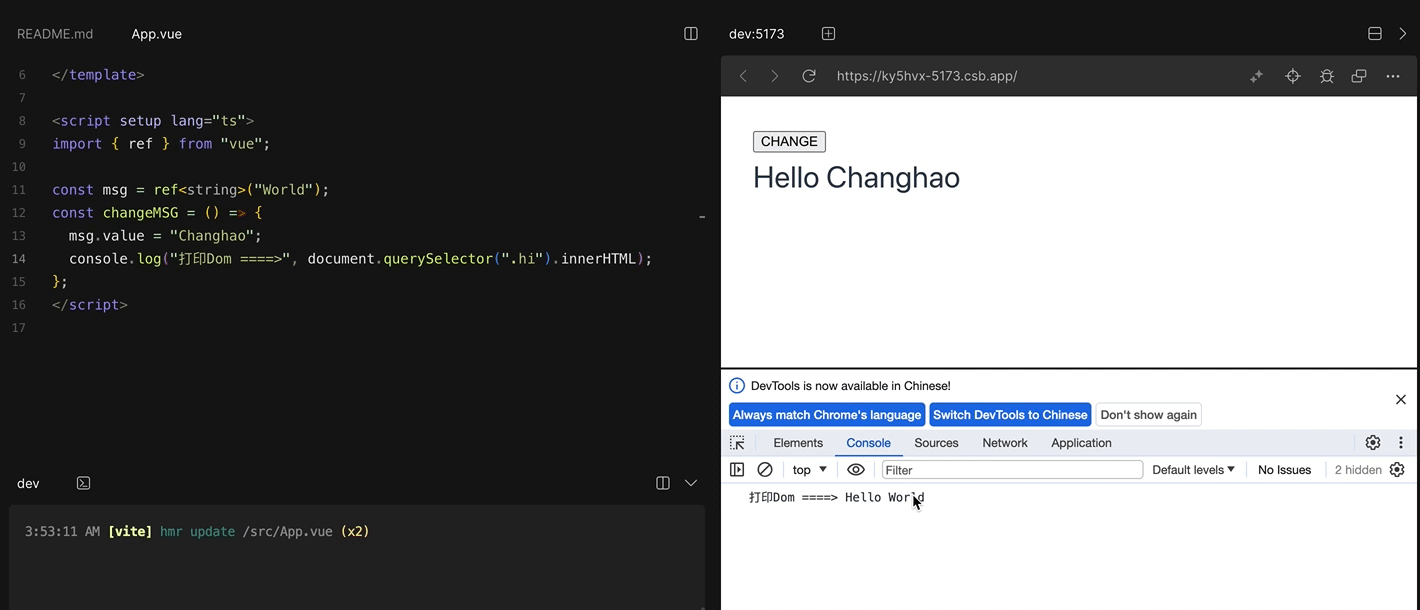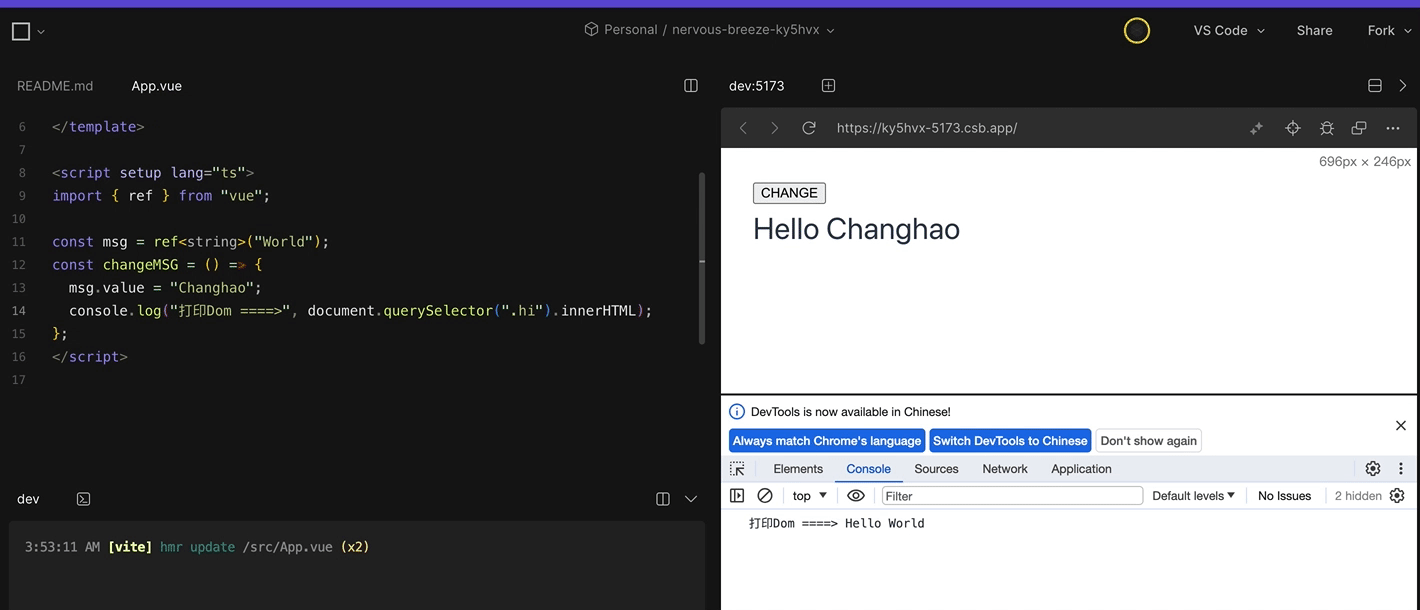
$nextTick的实现原理保证比较好的兼容性
Vue在更新data之后并不会立即更新DOM上的数据,就是说如果我们修改了data中的数据,再马上获取DOM上的值,我们取得的是旧值,但是我们把获取DOM上值的操作放进$nextTick里,就可以得到更新后得数据。
<template>
<div>
<button @click="changeMSG">CHANGE</button>
<h1 class="hi">Hello {{ msg }}</h1>
</div>
</template>
<script setup lang="ts">
import { ref } from "vue";
const msg = ref<string>("World");
const changeMSG = () => {
msg.value = "Changhao";
console.log("打印Dom ====>", document.querySelector(".hi").innerHTML);
};
</script>
<template>
<div>
<button @click="changeMSG">CHANGE</button>
<h1 class="hi">Hello {{ msg }}</h1>
</div>
</template>
<script setup lang="ts">
import { nextTick, ref } from "vue";
const msg = ref<string>("World");
const changeMSG = () => {
msg.value = "Changhao";
nextTick(() => {
console.log("打印Dom ====>", document.querySelector(".hi").innerHTML);
});
};
</script>

什么时候使用$nextTick
1、Vue⽣命周期的created()钩⼦函数进⾏的DOM操作⼀定要放在Vue.nextTick()的回调函数中,原因是在created()钩⼦函数执⾏的时候,DOM 其实并未进⾏任何渲染,⽽此时进⾏DOM操作⽆异于徒劳,所以此处⼀定要将DOM操作的js代码放进Vue.nextTick()的回调函数中。
2、当项⽬中改变data函数的数据,想基于新的dom做点什么,对新DOM⼀系列的js操作都需要放进Vue.nextTick()的回调函数中
$nextTick()执行原理
Vue 在更新 DOM 时是异步执行的。只要侦听到数据变化,Vue 将开启一个任务队列,并缓冲在同一时间循环中发生的所有数据变更。如果同一个 watcher 被多次触发,只会被推入到队列中一次。(这种在缓冲时去除重复数据对于避免不必要的计算和 DOM 操作是非常重要的)
然后,在下一个的事件循环“tick”中,Vue 刷新队列并执行任务队列 (已去重的) 工作。
Vue 在内部对异步队列尝试使用原生的 Promise.then(微任务)、MutationObserver 和 setImmediate,如果执行环境不支持,则会采用 setTimeout(fn, 0)(宏任务)代替。
当用户他懂一些网站的调试技术,他直接通过浏览器的调试工具台,改了你的HTML或者Css属性你该如何监听到这种行为?
MutationObserver https://developer.mozilla.org/zh-CN/docs/Web/API/MutationObserver 属于微任务
MutationObserver 接口提供了监视对 DOM 树所做更改的能力。它被设计为旧的 Mutation Events 功能的替代品,该功能是 DOM3 Events 规范的一部分。
<body>
<div id="target" style="width: 100px;height: 100px;background-color: red;"></div>
</body>
<script>
// 选择需要观察变动的节点
const targetNode = document.getElementById("target");
// 观察器的配置(需要观察什么变动)
const config = { attributes: true };
// 当观察到变动时执行的回调函数
const callback = function (mutationsList, observer) {
// Use traditional 'for loops' for IE 11
for (let mutation of mutationsList) {
console.log("The " + mutation.attributeName + " attribute was modified.")
}
};
// 创建一个观察器实例并传入回调函数
const observer = new MutationObserver(callback);
// 以上述配置开始观察目标节点
observer.observe(targetNode, config);
</script>
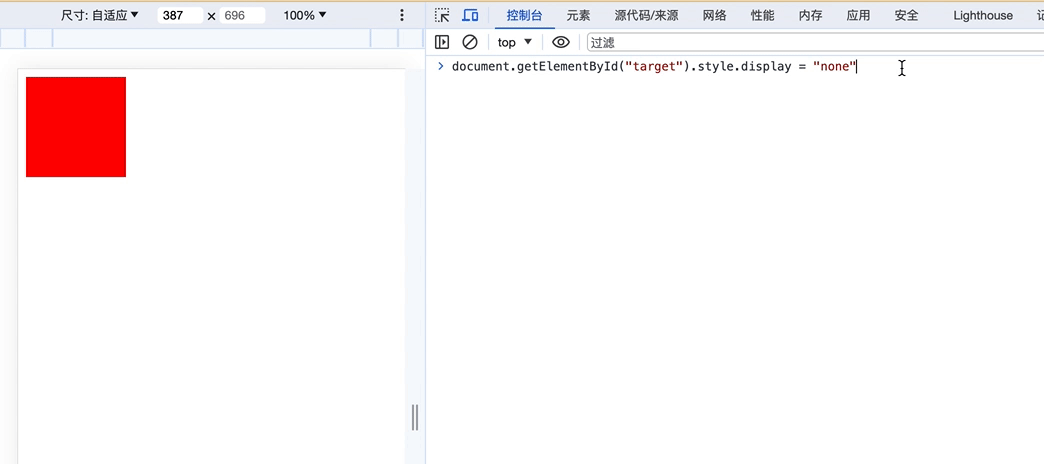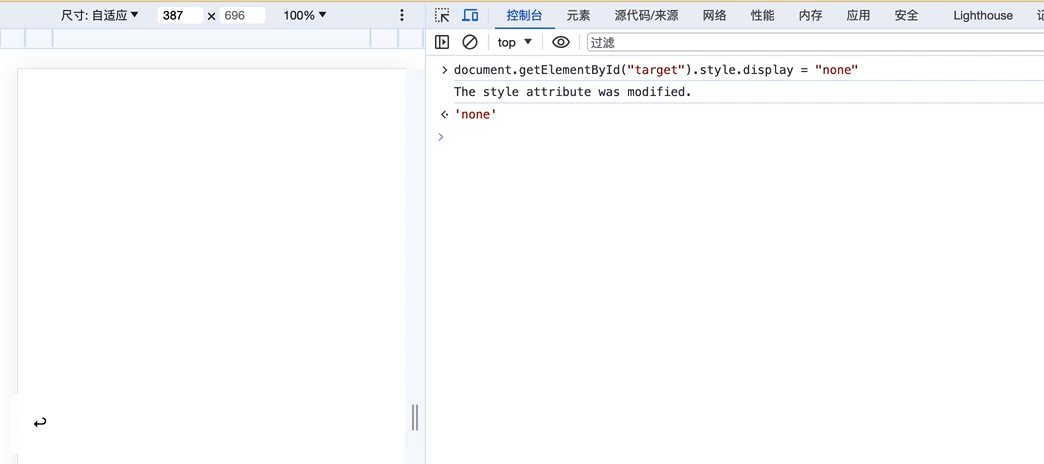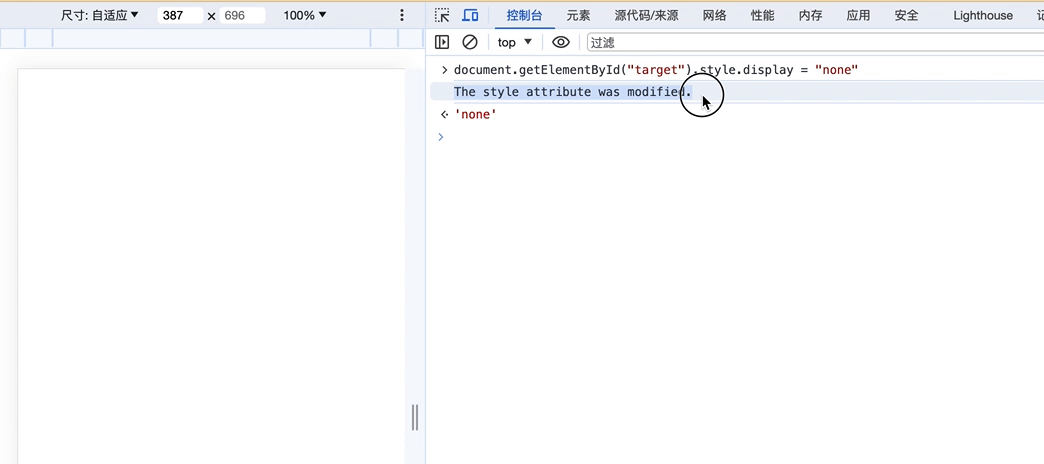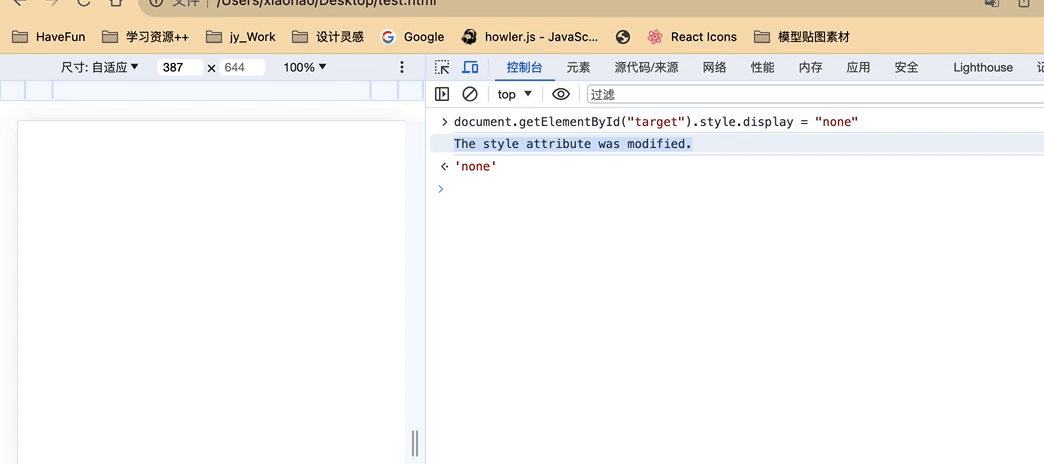
可以看到,上面我们通过在控制台输入代码
document.getElementById("target").style.display = "none"
来修改页面内容会被监听到
这样我们就可以保护我们的页面的HTML结构不被破坏,比如监听到外部的修改,我们就直接刷新页面!
评论区